사람 얼굴 표정에 따른 감정을 학습시키기 위해 이미지 크롤링을 시도해 보았다. Naver 보단 google이 좀
더 정확한 자료를 가지고 있다고 생각이 들어 구글로 시도해 보았다.
우선 selenium을 사용하기 위해서는 chromedriver가 필요하다
chromedriver.chromium.org/downloads
Downloads - ChromeDriver - WebDriver for Chrome
WebDriver for Chrome
chromedriver.chromium.org
위 사이트에 접속해 자신의 크롬브라우저 버전에 맞는 걸 선택하여 다운로드한다.
자신의 크롬 브라우저 버전은 다음과 같이 확인이 가능하다.
|
chrome://version |
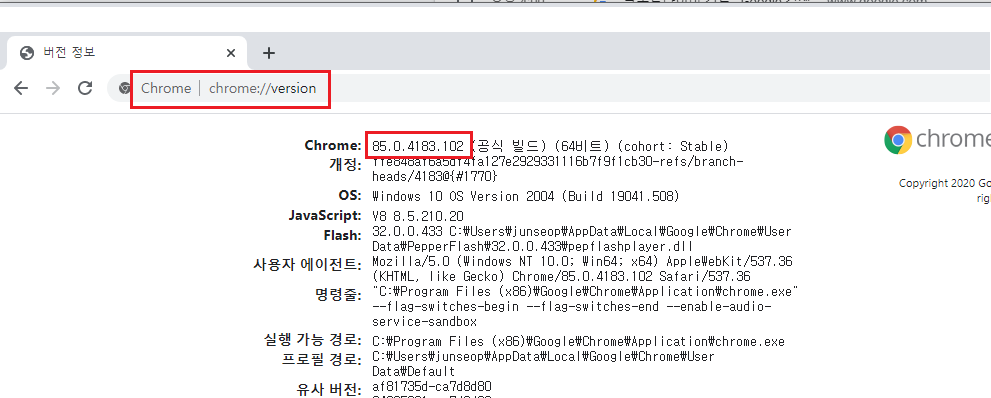
확인이 됐다면 다시 크롬브라우저 다운로드 사이트에 가서 버전에 맞게 선택하여 다운로드를 진행한다.

이런식으로 실행 파일이 하나 다운로드 되는데, 이 파일을 < 로컬 디스크(C:) > 에다 넣어 주었다.
(다른곳에 넣어도 되는지는 모름)
넣은 다음 폴더를 하나 만들어 주어야 함. 자신이 지정하여 폴더 만들고
18번 째 줄
|
[ image.screenshot(" |
저 부분을 지우고 자신의 폴더 위치를 작성해 준다
< crawl.py >
from selenium import webdriver
from bs4 import BeautifulSoup as soups
def search_selenium(search_name, search_path, search_limit) :
search_url = "https://www.google.com/search?q=" + str(search_name) + "&hl=ko&tbm=isch"
browser = webdriver.Chrome('c:/chromedriver.exe')
browser.get(search_url)
image_count = len(browser.find_elements_by_tag_name("img"))
print("로드된 이미지 개수 : ", image_count)
browser.implicitly_wait(2)
for i in range( search_limit ) :
image = browser.find_elements_by_tag_name("img")[i]
image.screenshot("c:/expression/Sad/" + str(i) + ".png")
browser.close()
if __name__ == "__main__" :
search_name = input("검색하고 싶은 키워드 : ")
search_limit = int(input("원하는 이미지 수집 개수 : "))
search_path = "Your Path"
# search_maybe(search_name, search_limit, search_path)
search_selenium(search_name, search_path, search_limit)

구글의 이미지이다.

내가 원하는 폴더에 구글의 이미지가 들어가는 것을 볼 수 있다.
